5 Databricks Performance Tips to Save Time and Money
As we process more and more data, performance is as critical as ever. The consumers of the data want it as soon as possible. And it seems like Ben Franklin had Cloud Computing in mind with this quote:
Time is Money. — Ben Franklin
Let’s look at five performance tips:
- Partition Selection
- Delta Cache
- Optimize with Z-order
- Optimize Write
- Merge by Partition
Assumptions
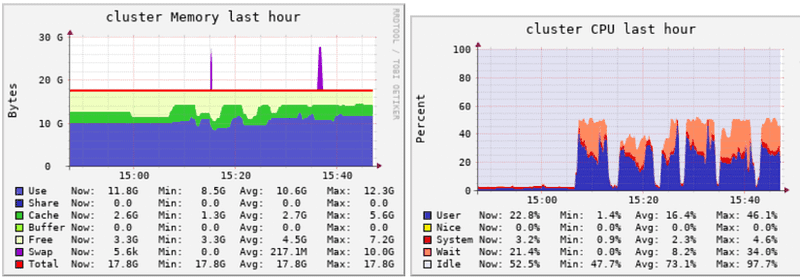
Adding bigger or more nodes to your cluster increases costs. There are also diminishing returns. You do not need 64 cores if you are only using 10. But you still need a minimum that matches your processing requirements. If your utilization looks like this, you must increase the size of your cluster:

Increase slowly until you have some breathing room. More acceptable range:
After we are comfortable with our cluster, we can focus on software performance. The slowest task is I/O. These tips address I/O in various ways to speed up your process.
To run some benchmarks, I used the Databricks’ Retail Dataset (databricks-datasets/online_retail/data-001/data.csv) and expanded it until I had 41.5 million rows. Then I created a delta table with 64k updates and 64k inserts. This dataset is very narrow. Production data will often contain hundreds of columns.
Partition Selection
The recommendation is to target a partition of at least 1GB. If this can be part of a business key, even better. That will cause partition pruning and reduce I/O. I saw a table with over 18,000 files. By changing the partition, I went down to 1,000 files and reduced the table size by 30%. This helps reduces I/O and will also help in later tips.
Delta Cache
Cache is 10x faster than disk. You must have enough memory to turn it on. But the cost savings of having the cluster active for less time will more than make up for a slighter large size.
While you are running your code, Databricks is even nice enough to tell you cache would be helpful.

You can turn it on in the notebook with:
spark.conf.set("spark.databricks.io.cache.enabled", "True")
Or you can turn it on automatically for the cluster in the Advanced Options.
spark.databricks.io.cache.enabled true
Optimize with Z-order
You can think of Optimize like an Index Rebuild in SQL Server. It takes all the partitions and rewrites them in the order you specify (business key). This will reduce the number of partitions and make the Merge statement much faster because the data is stored in key order, not randomly as the data came in.
With my test table, I started with 1608 files. After the Optimize command, it went down to 28 file s— a 98% improvement. The Merge statement time was reduced by 54%.
Optimize example:
%sql OPTIMIZE bigtable ZORDER BY (InvoiceNo, StockCode)
For large tables or many years of data, you can specify a Where clause to reduce processing time:
OPTIMIZE events WHERE date >= current_timestamp() - INTERVAL 1 day ZORDER BY (eventType)
Optimize Write
I do not see this feature used as much as the others. But it is recommended by Databricks for several scenarios, including Merge updates. For those who have an SSIS background, think of it as an Output Buffer. It collects rows to be written in an additional cache and then writes them in larger blocks, reducing the number of files written (read less overhead). It also offers an Auto Compaction setting. See Documentation for full details on when to use each.
Using Optimize Write, I reduced the number of files written to 35 vs. 28 after a full Optimize job. That compares to the original 1608 and only 0.5% difference than the Optimize command (without the z-ordering).
To turn it on in the notebook, run:
%sql set spark.databricks.delta.properties.defaults.autoOptimize.optimizeWrite = True;
If you have an existing table you want to change to Optimize Write, run:
%sql ALTER TABLE BigTable SET TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true);
Merge by partition
Dynamic file pruning is available in Databricks Runtime 6.1 and above. The sooner Databricks can eliminate I/O the better. If you have a partition that you will use for filtering, you can drastically improve performance. A common one is Date for the Raw layer. If you can use a partition as part of the merge join in Silver or Gold layers, you can gain the benefits there as well. The default thresholds to trigger pruning are 10 GB table with at least 1000 files. Otherwise, it is just as efficient to scan the whole table. When you are working with large tables, you can gain a 40x throughput.
Conclusion
- Partition Selection is important. Not too big or too small. Being able to apply it to joins and filters is the best.
- Delta Cache should be enabled. If you don’t have a cluster with it enabled automatically, turn it on in the settings.
- Optimize with Z-order. Start with join columns. You cannot Z-order by a partition. Start with Optimize weekly and adjust from there based on performance.
- Optimize Write with the optional auto compaction is useful in specific scenarios. See documentation for details.
- Merge by partition when possible. Like all optimizers, the earlier you can eliminate I/O and data size the better.
By applying these tips, I reduced a 300-plus column Dimension table load from 105 minutes to 3 minutes — a 97% throughput improvement. For a handful of large tables in the Datamart, 4-5 hours were shaved off the batch. That is almost 2,000 hours of processing per year.
Let us know how these tips work for you. And if you have a favorite tip, please comment and share.
Originally published at https://robertjblackburn.com on February 6, 2021.